pandas 1.什么是pandas Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
2.安装 3.基本使用 1.pandas的常用数据类型 1.Series 一维,带标签数组
2.DataFrame 二维,Series容器
2.Series 1.pandas之Series创建 1 2 3 4 5 6 import pandas as pd t1 = pd.Series ([1, 2, 3, 4, 5, 6] ) print ("t1\n" , t1) print (type(t1)
1 2 3 4 5 6 7 8 9 10 t1 索引 值 0 1 1 2 2 3 3 4 4 5 5 6 dtype: int64 <class 'pandas.core.series.Series' >
可以自己设定索引值
1 2 3 t2 = pd.Series([1 , 54 , 1544 , 4 , 974 ], index=list("abcde" ))print ("t2\n" , t2)
1 2 3 4 5 6 7 t2 a 1 b 54 c 1544 d 4 e 974 dtype : int64
可以通过字典来创建
1 2 3 temp_dict = {"name" : "zhangsan" , "age" : 18 , "tel" : 10086 } t3 = pd.Series (temp_dict) print ("t3\n" , t3)
1 2 3 4 5 t3 name zhangsanage 18 tel 10086 dtype : object
数据类型转换
1 2 t2 = t2.astype (float ) print ("t2\n" , t2)
1 2 3 4 5 6 7 t2 a 1 .0 b 54 .0 c 1544 .0 d 4 .0 e 974 .0 dtype : float64
2.pandas之Series切片和索引 切片:直接传入start end 或者步长即可
1 2 3 name zhangsanage 18 dtype: object
索引:一个的时候直接传入序号或者索引,多个的时候传入序号或者索引的列表
1 2 3 4 5 6 # 根据索引取值 print (t3[["name", "age"]] )print ("-" * 30 )# 获取不连续的值 print (t3[[0, 2]] )
1 2 3 4 5 6 7 name zhangsan age 18 dtype: object ----------------- name zhangsan tel 10086 dtype: object
获取索引和值
1 2 arange.index 获取索引 arange.values 获取值
Series对象本质上由两个数组构成,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 s = pd.Series(range(5 ))s .where(s > 0 )0 NaN1 1 .0 2 2 .0 3 3 .0 4 4 .0 s .where(s > 1 , 10 ) 0 10 .0 1 10 .0 2 2 .0 3 3 .0 4 4 .0 s .mask(s > 0 )0 0 .0 1 NaN2 NaN3 NaN4 NaN s .mask(s > 1 , 10 )0 0 .0 1 1 .0 2 10 .0 3 10 .0 4 10 .0
3.pandas之读取外部数据 读取csv文件,直接使用pandas.read_csv()
1 2 3 4 5 import pandas as pd df = pd.read_csv ("dogNames2.csv" ) print (df)
读取数据库,先要创建连接并定义查询语句,使用pandas.read_sql()读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pandas as pd import pymysql db_conn = pymysql.connect( host ="localhost" , port =3306, user ="root" , password ="202124" , database ="ssm_db" , charset ="utf8" , ) sql = "select * from tbl_book" spl_content = pd.read_sql(sql, con =db_conn) print (spl_content)
4.DataFrame 1.pandas之DataFrame创建 1 2 3 4 5 6 import pandas as pdimport numpy as np# index 设置行索引,columns 设置列索引 t1 = pd.DataFrame(np.arange(12 ).reshape(3 , 4 ),index =list("abc"), columns =list("wxyz")) print(t1)
1 2 3 4 w x y z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
2.通过字典创建DataFrame 1 2 3 4 5 6 7 d1 = { "name" : ["zhangsan" , "lisi" , "wangu" ] , "age" : [18, 19, 20] , "tel" : [110, 119, 120] , } t2 = pd.DataFrame (d1) print (t2)
1 2 3 4 name age tel 0 zhangsan 18 110 1 lisi 19 119 2 wangu 20 120
3.通过列表创建DataFrame 1 2 3 4 5 6 7 8 d2 = [ {"name" : "zhangsan" , "age" : 18, "tel" : 110}, {"name" : "lisi" , "age" : 19, "tel" : 119}, {"name" : "wangu" , "age" : 20, "tel" : 120}, ] t3 = pd.DataFrame(d2) print(t3)
1 2 3 0 zhangsan 18 110 1 lisi 19 119 2 wangu 20 120
4.pandas的方法 DataFramel的基础属性
DataFrame整体情况查询
1 2 3 df = df.sort_values(by ="Count_AnimalName" , ascending =False )
5.pandas之取行或者列 1 2 3 4 5 6 7 print (df [:20])print (df ["Row_Labels" ])print (df [:5]["Row_Labels" ])
1.pandas之loc df.loc 通过标签 索引行数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import pandas as pd import numpy as np df = pd.DataFrame(np.arange(12).reshape(3, 4), index =list("abc"), columns =list("wxyz")) print (df)t1 = df.loc["a" ] print ("t1\n" , t1)print ("-" * 30)t2 = df.loc[:, "w" ] print ("t2\n" , t2)print ("-" * 30)t3 = df.loc["a" , "w" ] print ("t3\n" , t3)print ("-" * 30)t4 = df.loc["a" , ["w" , "z" ]] print ("t4\n" , t4)print ("-" * 30)t5 = df.loc[["a" , "b" , "c" ], "y" ] print ("t5\n" , t5)print ("-" * 30)t6 = df.loc["a" :"c" , "x" ] print ("t6\n" , t6)print ("-" * 30)t7 = df.loc[["a" , "b" , "c" ]] print ("t7\n" , t7)print ("-" * 30)t8 = df.loc[:, ["x" , "z" ]] print ("t8\n" , t8)print ("-" * 30)t9 = df.loc[["a" , "b" ], ["w" , "x" ]] print ("t9\n" , t9)print ("-" * 30)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 w x y z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 t1 w 0 x 1 y 2 z 3 Name: a, dtype: int32 ------------------------------ t2 a 0 b 4 c 8 Name: w, dtype: int32 ------------------------------ t3 0 ------------------------------ t4 w 0 z 3 Name: a, dtype: int32 ------------------------------ t5 a 2 b 6 c 10 Name: y, dtype: int32 ------------------------------ t6 a 1 b 5 c 9 Name: x, dtype: int32 ------------------------------ t7 w x y z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 ------------------------------ t8 x z a 1 3 b 5 7 c 9 11 ------------------------------ t9 w x a 0 1 b 4 5
2.pandas之iloc df.iloc 通过位置 获取行数据
iloc的用法大致和loc的用法差不多,loc主要是通过索引来寻找值,iloc则是通过位置(坐标[从0开始])
6.pandas之布尔索引 当条件为一个的时候,可以直接通过<=>来使用
当条件为多个的时候,需要使用&(且)或者|(或)符号来连接,如:
1 df [(800 < df ["Count_AnimalName" ]) & (df ["Count_AnimalName" ] < 1000)]
7.pandas之字符串方法
使用方法(会对每一个字符串进行操作)
8.缺失数据的处理 判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式1:删除NaN所在的行列dropna (axis=0, how=’any’, inplace=False)
处理方式2:填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
处理为0的数据:t[t==0]=np.nan
当然并不是每次为0的数据都需要处理
计算平均值等情况,nan是不参与计算的,但是0会
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import pandas as pd import numpy as np df = pd.DataFrame(np.arange(12).reshape(3, 4), index =list("abc"), columns =list("wxyz")) df.iloc[1:, :2] = np.nan df.iloc[0, 2] = np.nan print (df)print ("-" * 30)print (pd.isnull(df))print ("-" * 30)print (pd.notnull(df))print ("-" * 30)print (df[pd.notnull(df["w" ])])print ("-" * 30)print (pd.notnull(df["w" ]))print ("-" * 30)df.dropna(axis =0, how ="all" , inplace =True ) print (df)print ("-" * 30)print (df.fillna(df.mean()))print ("-" * 30)df["y" ] = df["y" ].fillna(df["y" ].mean()) print (df)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 w x y z a 0.0 1.0 NaN 3 b NaN NaN 6.0 7 c NaN NaN 10.0 11 ------------------------------ w x y z a False False True False b True True False False c True True False False ------------------------------ w x y z a True True False True b False False True True c False False True True ------------------------------ w x y z a 0.0 1.0 NaN 3 ------------------------------ a True b False c False Name: w, dtype: bool ------------------------------ w x y z a 0.0 1.0 NaN 3 b NaN NaN 6.0 7 c NaN NaN 10.0 11 ------------------------------ w x y z a 0.0 1.0 8.0 3 b 0.0 1.0 6.0 7 c 0.0 1.0 10.0 11 ------------------------------ w x y z a 0.0 1.0 8.0 3 b NaN NaN 6.0 7 c NaN NaN 10.0 11
9.pandas常用统计方法
方法
作用
mean
平均分
max
最大值
argmax
最大值位置
min
最小值
argmin
最小值位置
median
中值
10.数据合并 pandas包中,进行数据合并有join()、merge()、concat(), append()四种方法。它们的区别是:
df.join() 相同行索引的数据被合并在一起,因此拼接后的行数不会增加(可能会减少)、列数增加;
df.merge()通过指定的列索引进行合并,行列都有可能增加;merge也可以指定行索引进行合并;
pd.concat()通过axis参数指定在水平还是垂直方向拼接;
df.append()在DataFrame的末尾添加一行或多行;大致等价于pd.concat([df1,df2],axis=0,join=’outer’)。
1.数据合并之join join:默认情况下他是把行索引相同的数据合并到一起
DataFrame.join(other, on=None, how=’left’, lsuffix=’’, rsuffix=’’, sort=False)
参数
说明
other
右表, DataFrame, Series, or list of DataFrame
on
关联字段, 是关联index的
how
拼接方式,默认left,{‘left’, ‘right’, ‘outer’, ‘inner’}
lsuffix
左表相同列索引的后缀
rsuffix
右表相同列索引的后缀
sort
根据连接键对合并后的数据进行排列,默认为False
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import pandas as pd import numpy as np df1 = pd.DataFrame(np.ones((2, 4)), index=["A" , "B" ], columns =list("abcd")) print (df1)print ("-" * 30)df2 = pd.DataFrame(np.zeros((3, 3)), index=["A" , "B" , "C" ], columns =list("xyz")) print (df2)print ("-" * 30)df3 = df1.join(df2) print (df3)print ("-" * 30)df4 = df2.join(df1) print (df4)print ("-" * 30)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 a b c d A 1.0 1.0 1.0 1.0 B 1.0 1.0 1.0 1.0 ------------------------------ x y z A 0.0 0.0 0.0 B 0.0 0.0 0.0 C 0.0 0.0 0.0 ------------------------------ a b c d x y z A 1.0 1.0 1.0 1.0 0.0 0.0 0.0 B 1.0 1.0 1.0 1.0 0.0 0.0 0.0 ------------------------------ x y z a b c d A 0.0 0.0 0.0 1.0 1.0 1.0 1.0 B 0.0 0.0 0.0 1.0 1.0 1.0 1.0 C 0.0 0.0 0.0 NaN NaN NaN NaN
2.数据合并之merge merge:按照指定的列把数据按照一定的方式合并到一起
参数
说明
right
右表, DataFrame, Series, or list of DataFrame
how
拼接方式,默认inner,{‘left’, ‘right’, ‘outer’, ‘inner’}
on
默认None,自动根据相同列拼接。关联字段, 是关联columns的,必须同时存在于2个表中
left_on
默认None,左表中用作连接键的列索引
right_on
默认None,右表中用作连接键的列索引
left_index
默认Flase,是否将左表中的行索引用作连接键
right_index
默认Flase,是否将右表中的行索引用作连接键
sort
根据连接键对合并后的数据进行排列,默认为Flase
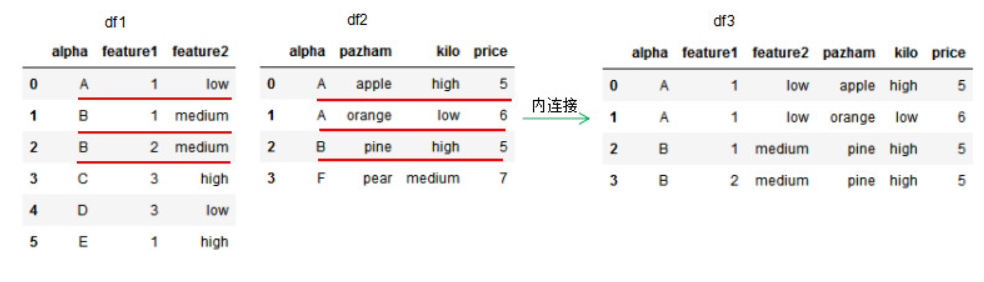
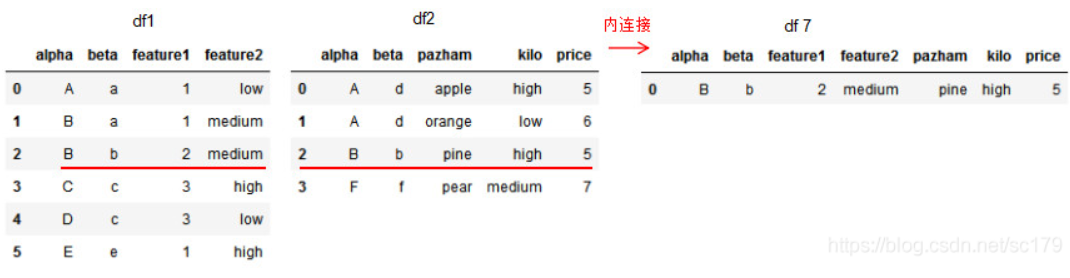
1.1 内连接 how=‘inner’,on=设置连接的共有列名。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import pandas as pdimport numpy as npdf1 = pd.DataFrame({'alpha' :['A' ,'B' ,'B' ,'C' ,'D' ,'E' ], 'feature1' :[1 ,1 ,2 ,3 ,3 ,1 ], 'feature2' :['low' ,'medium' ,'medium' ,'high' ,'low' ,'high' ]}) df2 = pd.DataFrame({'alpha' :['A' ,'A' ,'B' ,'F' ], 'pazham' :['apple' ,'orange' ,'pine' ,'pear' ], 'kilo' :['high' ,'low' ,'high' ,'medium' ], 'price' :np.array([5 ,6 ,5 ,7 ])}) df3 = pd.merge(df1,df2,how='inner' ,on ='alpha' ) print (df1)print (df2)print (df3)
取共同列alpha值的交集进行连接。
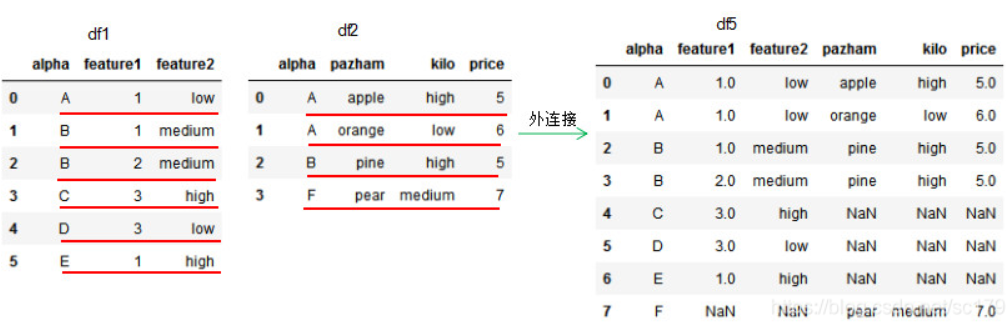
1.2 外连接 how=‘outer’,dataframe的链接方式为外连接,我们可以理解基于共同列的并集进行连接,参数on设置连接的共有列名。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 df1 = pd.DataFrame({'alpha' :['A' ,'B' ,'B' ,'C' ,'D' ,'E' ], 'feature1' :[1,1,2,3,3,1], 'feature2' :['low' ,'medium' ,'medium' ,'high' ,'low' ,'high' ]}) df2 = pd.DataFrame({'alpha' :['A' ,'A' ,'B' ,'F' ], 'pazham' ['apple' ,'orange' ,'pine' ,'pear' ], 'kilo' :['high' ,'low' ,'high' ,'medium' ], 'price' :np.array([5,6,5,7])}) df5 = pd.merge(df1,df2,how ='outer' ,on='alpha') print (df1)print (df2)print (df5)
若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
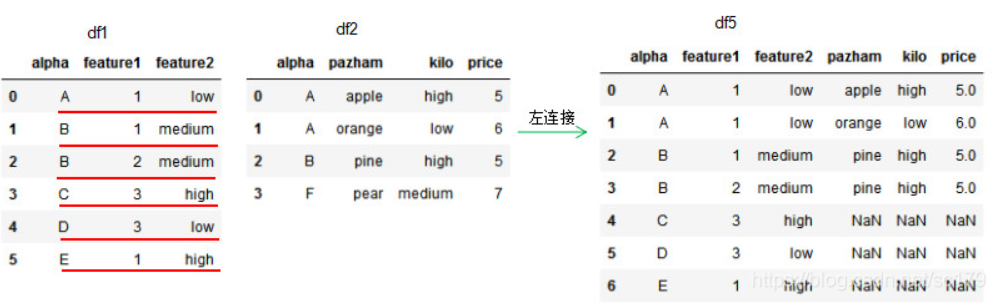
1.3 左连接 how=‘left’,dataframe的链接方式为左连接,我们可以理解基于左边位置dataframe的列进行连接,参数on设置连接的共有列名。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 df1 = pd.DataFrame({'alpha' :['A' ,'B' ,'B' ,'C' ,'D' ,'E' ], 'feature1' :[1,1,2,3,3,1], 'feature2' :['low' ,'medium' ,'medium' ,'high' ,'low' ,'high' ]}) df2 = pd.DataFrame({'alpha' :['A' ,'A' ,'B' ,'F' ], 'pazham' :['apple' ,'orange' ,'pine' ,'pear' ], 'kilo' :['high' ,'low' ,'high' ,'medium' ], 'price' :np.array([5,6,5,7])}) df5 = pd.merge(df1,df2,how ='left' ,on='alpha') print (df1)print (df2)print (df5)
因为df2的连接列alpha有两个’A’值,所以左连接的df5有两个’A’值,若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
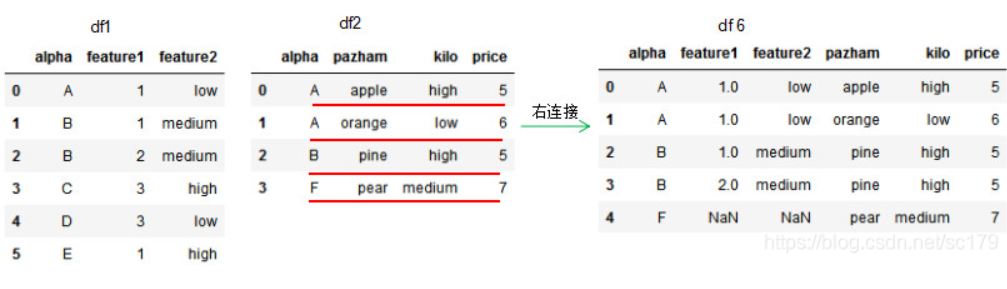
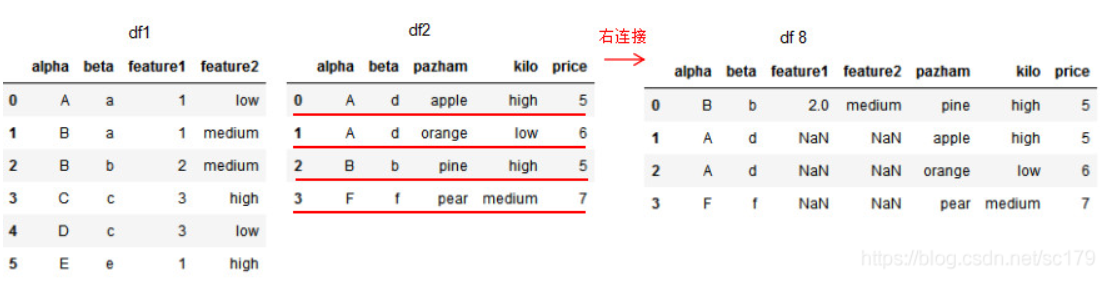
1.4 右连接 how=‘right’,dataframe的链接方式为左连接,我们可以理解基于右边位置dataframe的列进行连接,参数on设置连接的共有列名。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 df1 = pd.DataFrame({'alpha' :['A' ,'B' ,'B' ,'C' ,'D' ,'E' ], 'feature1' :[1,1,2,3,3,1], 'feature2' :['low' ,'medium' ,'medium' ,'high' ,'low' ,'high' ]}) df2 = pd.DataFrame({'alpha' :['A' ,'A' ,'B' ,'F' ], 'pazham' :['apple' ,'orange' ,'pine' ,'pear' ], 'kilo' :['high' ,'low' ,'high' ,'medium' ], 'price' :np.array([5,6,5,7])}) df6 = pd.merge(df1,df2,how ='right' ,on='alpha') print (df1)print (df2)print (df6)
因为df1的连接列alpha有两个’B’值,所以右连接的df6有两个’B’值。若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
1.5 基于多列的连接算法 多列连接的算法与单列连接一致,本节只介绍基于多列的内连接和右连接,读者可自己编码并按照本文给出的图解方式去理解外连接和左连接。
多列的内连接:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 df1 = pd.DataFrame({'alpha' :['A' ,'B' ,'B' ,'C' ,'D' ,'E' ], 'beta' :['a' ,'a' ,'b' ,'c' ,'c' ,'e' ], 'feature1' :[1,1,2,3,3,1], 'feature2' :['low' ,'medium' ,'medium' ,'high' ,'low' ,'high' ]}) df2 = pd.DataFrame({'alpha' :['A' ,'A' ,'B' ,'F' ], 'beta' :['d' ,'d' ,'b' ,'f' ], 'pazham' :['apple' ,'orange' ,'pine' ,'pear' ], 'kilo' :['high' ,'low' ,'high' ,'medium' ], 'price' :np.array([5,6,5,7])}) df7 = pd.merge(df1,df2,on=['alpha' ,'beta' ],how ='inner' ) print (df1)print (df2)print (df7)
多列的右连接:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 df1 = pd.DataFrame({'alpha' :['A' ,'B' ,'B' ,'C' ,'D' ,'E' ], 'beta' :['a' ,'a' ,'b' ,'c' ,'c' ,'e' ], 'feature1' :[1,1,2,3,3,1], 'feature2' :['low' ,'medium' ,'medium' ,'high' ,'low' ,'high' ]}) df2 = pd.DataFrame({'alpha' :['A' ,'A' ,'B' ,'F' ], 'beta' :['d' ,'d' ,'b' ,'f' ], 'pazham' :['apple' ,'orange' ,'pine' ,'pear' ], 'kilo' :['high' ,'low' ,'high' ,'medium' ], 'price' :np.array([5,6,5,7])}) df8 = pd.merge(df1,df2,on=['alpha' ,'beta' ],how ='right' ) print (df1)print (df2)print (df8)
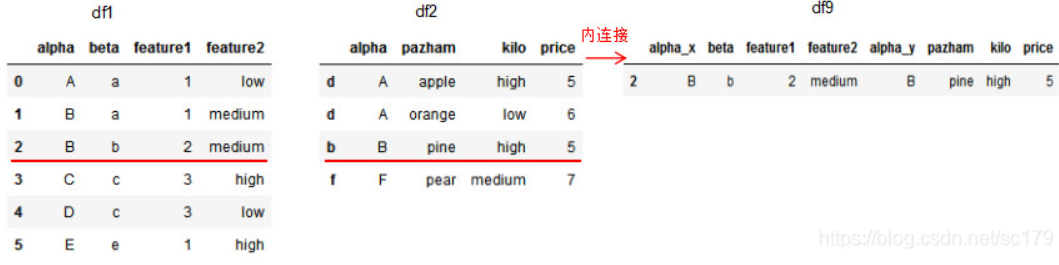
1.6 基于index的连接方法 基于column的连接方法,merge方法亦可基于index连接dataframe。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 df1 = pd.DataFrame({'alpha' :['A' ,'B' ,'B' ,'C' ,'D' ,'E' ], 'beta' :['a' ,'a' ,'b' ,'c' ,'c' ,'e' ], 'feature1' :[1,1,2,3,3,1], 'feature2' :['low' ,'medium' ,'medium' ,'high' ,'low' ,'high' ]}) df2 = pd.DataFrame({'alpha' :['A' ,'A' ,'B' ,'F' ], 'pazham' :['apple' ,'orange' ,'pine' ,'pear' ], 'kilo' :['high' ,'low' ,'high' ,'medium' ], 'price' :np.array([5,6,5,7])}, index=['d' ,'d' ,'b' ,'f' ]) df9 = pd.merge(df1,df2,how ='inner' ,left_on='beta',right_index=True) print (df1)print (df2)print (df9)
3.数据合并之concat
按方向拼接(pd.concat()按行或列进行合并,axis参数决定拼接方向)
pd.concat([data1, data2], axis=0) 默认axis=0,垂直方向拼接,默认join=’outer’并集拼接;当join=’inner’进行交集拼接时,对列索引取交集;
pd.concat([data1, data2], axis=1) 水平方向拼接,默认并集拼接;当join=’inner’进行交集拼接时,对行索引取交集;
并集拼接时,若列标签均不相同,则行列标签数量均会增加,未同时存在在2个表中的字段的values为NaN;
常用参数
说明
objs
要合并的DataFrame或Series,以列表传入。如[df1, df2]
axis
拼接方向,{0/’index’, 1/’columns’},默认0,代表垂直方向拼接;1代表水平方向拼接
join
拼接方式,默认outer并集,{‘outer’, ‘inner’} ,inner交集
ignore_index
默认False,是否需要重置索引。
4.数据合并之append
和pd.concat方法的区别:
append只能做行的拼接
append方法是外连接
相同点:
append可以支持多个DataFrame的拼接
append大致等同于 pd.concat([df1,df2],axis=0,join='outer')
常用参数
说明
other
要被拼接进去的对象
ignore_index
是否需要重置索引,默认False不重置,会保留other的原索引
verify_integrity
默认False,是否在创建具有重复项的索引时引发ValueError
sort
默认False,否,是否在df和other的列不对齐时,对列进行排序
11.分组和聚合 DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True,=False, **kwargs)
1 2 3 4 5 6 7 8 9 10 11 12 13 by :分组字段,接收list、str、mapping 或generator,用于确定进行分组的键值。如果传入的是一个函数则对索引进行计算并分组;如果传入的是一个字典或者series则用字典或者series的值作为分组依据;如果传入一个numpy数组则用数据的元素作为分组依据;如果传入的是字符串或者字符串列表则用这些字符串所代表的字段作为分段依据axis :指定切分方向,默认为0 ,表示沿着行切分,对列进行操作 level :表示标签所在级别,默认为None as_index:表示聚合后的聚合标签是否以DataFrame索引形式输出,默认为True ;当设置为False 时相当于加了reset_index功能 sort :通过sort参数指定是否对输出结果按索引排序,默认为True group_keys :表示是否显示分组标签的名称,默认为True squeeze :表示是否在允许的情况下对返回数据进行降维,默认为True
分组后使用count方法对每列进行聚合计算
聚合函数为每个组返回单个聚合值。当创建了groupby对象,就可以对分组数据执行多个聚合操作。比较常用的是通过聚合函数或等效的agg方法聚合。常用的聚合函数如下表:
函数名
说明
count
分组中非空值的数量
sum
非空值的和
mean
非空值的平均值
median
非空值的中位数
std、var
无偏标准差和方差
min、max
非空值的最小和最大值
prod
非空值的积
first、last
第一个和最后一个非空值
12.索引和复合索引 简单的索引操作:
获取index:df.index
指定index :df.index = [‘x’,’y’]
重新设置index : df.reindex(list(“abcedf”))
指定某一列作为index :df.set_index(“Country”,drop=False)
返回index的唯一值:df.set_index(“Country”).index.unique()
13.pandas中的时间序列 pd.date_range(start=None, end=None, periods=None, freq=’D’)
start和end以及freq配合能够生成start和end范围 内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开始的频率为freq的periods 个时间索引
1 2 3 4 5 6 7 8 9 10 11 12 13 import pandas as pd df1 = pd.date_range(start ="20230101" , end ="20231231" , freq ="10D" ) print (df1)df2 = pd.date_range(start ="20230101" , periods =10, freq ="M" ) print (df2)df3 = pd.date_range(start ="20230101" , periods =10, freq ="H" ) print (df3)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 DatetimeIndex(['2023-01-01 ', '2023-01-11 ', '2023-01-21 ', '2023-01-31 ', '2023-02-10 ', '2023-02-20 ', '2023-03-02 ', '2023-03-12 ', '2023-03-22 ', '2023-04-01 ', '2023-04-11 ', '2023-04-21 ', '2023-05-01 ', '2023-05-11 ', '2023-05-21 ', '2023-05-31 ', '2023-06-10 ', '2023-06-20 ', '2023-06-30 ', '2023-07-10 ', '2023-07-20 ', '2023-07-30 ', '2023-08-09 ', '2023-08-19 ', '2023-08-29 ', '2023-09-08 ', '2023-09-18 ', '2023-09-28 ', '2023-10-08 ', '2023-10-18 ', '2023-10-28 ', '2023-11-07 ', '2023-11-17 ', '2023-11-27 ', '2023-12-07 ', '2023-12-17 ', '2023-12-27 '], dtype='datetime64[ns]', freq='10D') DatetimeIndex(['2023-01-31 ', '2023-02-28 ', '2023-03-31 ', '2023-04-30 ', '2023-05-31 ', '2023-06-30 ', '2023-07-31 ', '2023-08-31 ', '2023-09-30 ', '2023-10-31 '], dtype='datetime64[ns]', freq='M') DatetimeIndex(['2023-01-01 00:00:00', '2023-01-01 01:00:00', '2023-01-01 02:00:00', '2023-01-01 03:00:00', '2023-01-01 04:00:00', '2023-01-01 05:00:00', '2023-01-01 06:00:00', '2023-01-01 07:00:00', '2023-01-01 08:00:00', '2023-01-01 09:00:00'], dtype='datetime64[ns]', freq='H')
关于频率的更多缩写
PeriodIndex
DatetimeIndex可以理解为时间戳
PeriodIndex可以理解为时间段